Have you ever come across a scenario where your data looks good until you import it into MySQL? The data you’ve imported into MySQL is suddenly displayed as “???”, letting you wonder what’s wrong in your database configuration. The reason of this problem is a character set or collation mismatch – when worked with properly, character sets and collations can make our work with MySQL a dream, or a nightmare.
Collations and character sets have their place – they let MySQL decide where from we acquired data and how best to work with it internally; since we can choose from a whole sea of charsets and collations within the RDBMS, properly matching them for our use case is crucial.
What are Character Sets and Collations?
Put Simply, character sets define what characters are considered to be “legal” in a certain string, while collations are a set of rules that tell MySQL how to sort characters within the string. That’s why when we input, for example, data from a Chinese, Taiwanese, or Russian source without fully preparing for it, we’ll see “????” instead of our character string – our database won’t be prepared.
Character sets and collations aren’t unique to MySQL, though – they are relevant to every database management system we find ourselves using, including Oracle, Sybase, TimescaleDB, or, you’ve guessed it, any flavor of MySQL as well.
A proper match of character sets and collations is crucial if we want to work with data from “exotic” (not english) sources. Some of the character sets and collations considered “default” in MySQL are as follows:
- The default character set is latin1 with a collation of latin1_swedish_ci. This character set is a fit if we want to work with Swedish characters (MySQL is built by Swedish people), or Russian characters.
- If we use Chinese characters, the collation that would be a fit would be big5_chinese_ci with a charset of big5.
- For general use cases, we should use a character set of utf8mb4 with a collation of utf8mb4_general_ci (or utf8mb4_unicode_ci.) The reason behind this is that utf8mb4 is considered the “true” form of utf8 since it can support 4 bytes in a character while utf8 only supports 3. For more “corner” use cases, there’s the utf8mb4_unicode_ci variation,
- In the case of Hebrew characters, we should use a Hebrew charset with a collation of hebrew_general_ci. You get the point – there are multiple character sets and collations we are able to choose to employ for a concrete use case. For a complete list, connect to MySQL and issue a SHOW CHARACTER SET query.
Some of the results derived by that query are shown below:
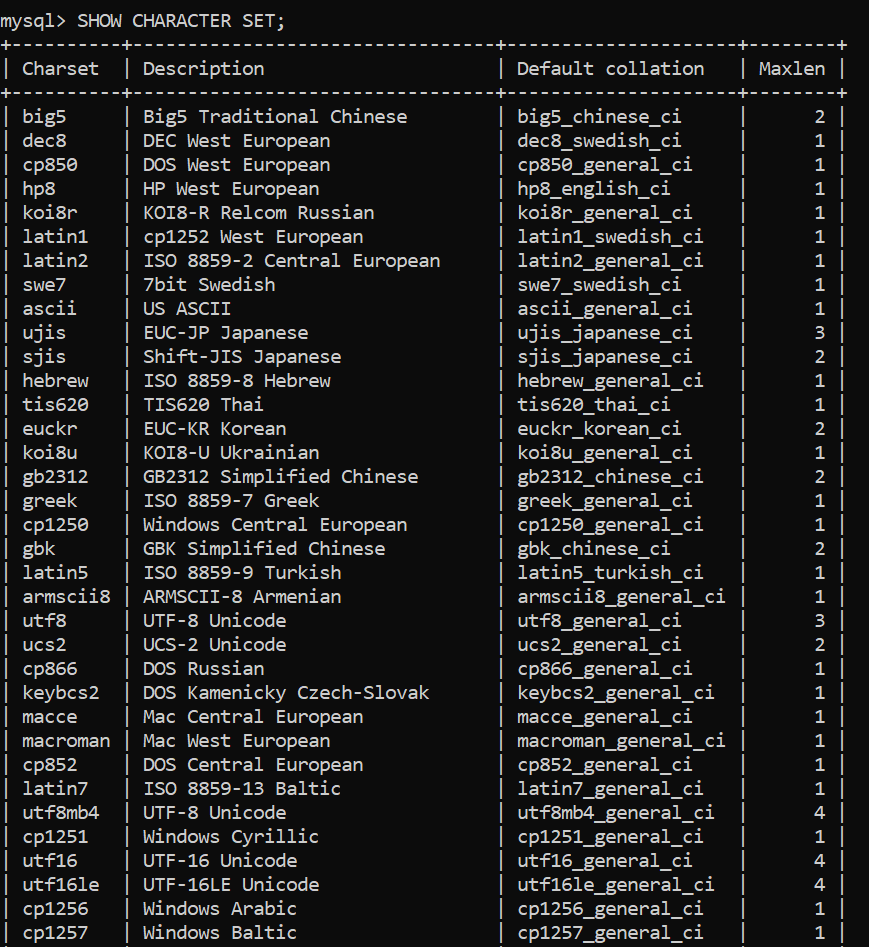
MySQL will even provide a description of the character set and collation, allowing you to make easier decisions.
Properly Matching Character Sets and Collations
As you can tell by now, there are numerous character sets and collations we are able to choose from. Properly matching them is a skill every database administrator gets hold of with experience and with the help of MySQL (see above) – there inevitably will be cases where we mismatch character sets and collations, and get to know of it after the fact, but that’s not a very big issue – and it allows us to learn as well.
Some of you might know that some character sets consume more space on the disk than others do and once we have a lot of data that could become an issue, but here’s a lifehack: to overcome such an issue, we can issue a SHOW CHARACTER SET query and look at the “Maxlen” column (see above), or if we are dealing with UTF8, closely observe a part of the collation that is in use – e.g. “utf8mb4” will use 4 bytes instead of 3, etc.
With all these character sets and collations, properly matching them all might be a challenge if we are not educated on how databases work – even with the query given above, MySQL doesn’t tell us all that much if we’re not aware of the basics of charsets and collations. Don’t worry much, though – the description, though very short and to the point, should become a good starting point.
There’s no need to get too in depth on this one – look at the language descriptors after the charset and decide from there. Before deciding, though, you should use when to use different character sets and how to choose.
When to Use Different Character Sets?
People mostly use different character sets (i.e. not the default ones provided by MySQL) when they’re working with data from sources that MySQL would consider “exotic” (i.e. not English or Swedish of nature.) The closest definition on when you should switch to a different character set is “whenever you feel like your data belongs to an “exotic” country.
Think of the countries people from Europe are vacationing in: Turkey, Dubai, Spain, Portugal, etc. There are countries that are different beasts in and of themselves, amongst them is China, Taiwan, Japan, South Korea, Russia and a couple of others (we mean those countries that talk in completely different alphabets than the one we are used to.)
If you are not sure on when to make the switch and to what character set, see the documentation for some more explanation, but the explanation above should put you closer towards your goal.
Going Beyond Character Sets and Collations
Once you’ve properly matched character sets and collations, there a couple more things you need to be aware of for your database to perform at the very best of its capability – you need to keep a very close eye on your database performance and availability as well.
Not even talking about security – everyone knows that after COVID, the number of data breaches have continued to rise and rise and no one wants their database infrastructure to become the next target.
For that, consider employing database monitoring inside of your database infrastructure – database monitoring tools such as the ones provided by dbWatch or database vendors themselves will let you see how your database is doing from availability, performance, or security points of view all the time. The problem is, though, that database management software solutions provided by database vendors (think MariaDB, Percona, TimescaleDB, Redis, and the like), are generally expensive and you’re paying more for the name than software capabilities.
Discover how dbWatch seamlessly supports diverse character sets—start your 90-day free trial today and experience the difference firsthand!