You have a solid database architecture. You spent all the requisite time needed making sure your models are normalised in a way to provide the cleanest structures. However, reality being what it is, there are occasional problems.
Rarely is any database complete and perfect the first time it is deployed.
Sure, you can handle any problems that arise at first; every now and then something doesn’t run the way it is supposed to. You can see most of what you need through a quick examination of the logs; there are few slow-downs, but for the most part, due to your diligence, you can fix it with a few tweaks. But now the business needs have grown and you’re needing to create more and more instances.
This is where the trouble begins You’ve reached a point where you now have hundreds of instances, on as many virtual servers. Maybe everything is functioning whenever you look at one instance at one point in time, but you’re seeing signs of slowdowns in individual locations and you are unsure of what is causing it.
You’ve reached a point where you now have hundreds of instances, on as many virtual servers. Maybe everything is functioning whenever you look at one instance at one point in time, but you’re seeing signs of slowdowns in individual locations and you are unsure of what is causing it.
You have this sneaky suspicion that this is happening in more places than you can manage. Something may have crashed but you have no idea that it even occurred. Indexes may have been dropped, but you get no indication. You might find it in the logs, but it is extremely time-consuming if you don’t know
where to look. Not only that, pouring through them becomes arduous, and by the time you’ve found a problem in one place, new ones have cropped up somewhere else.
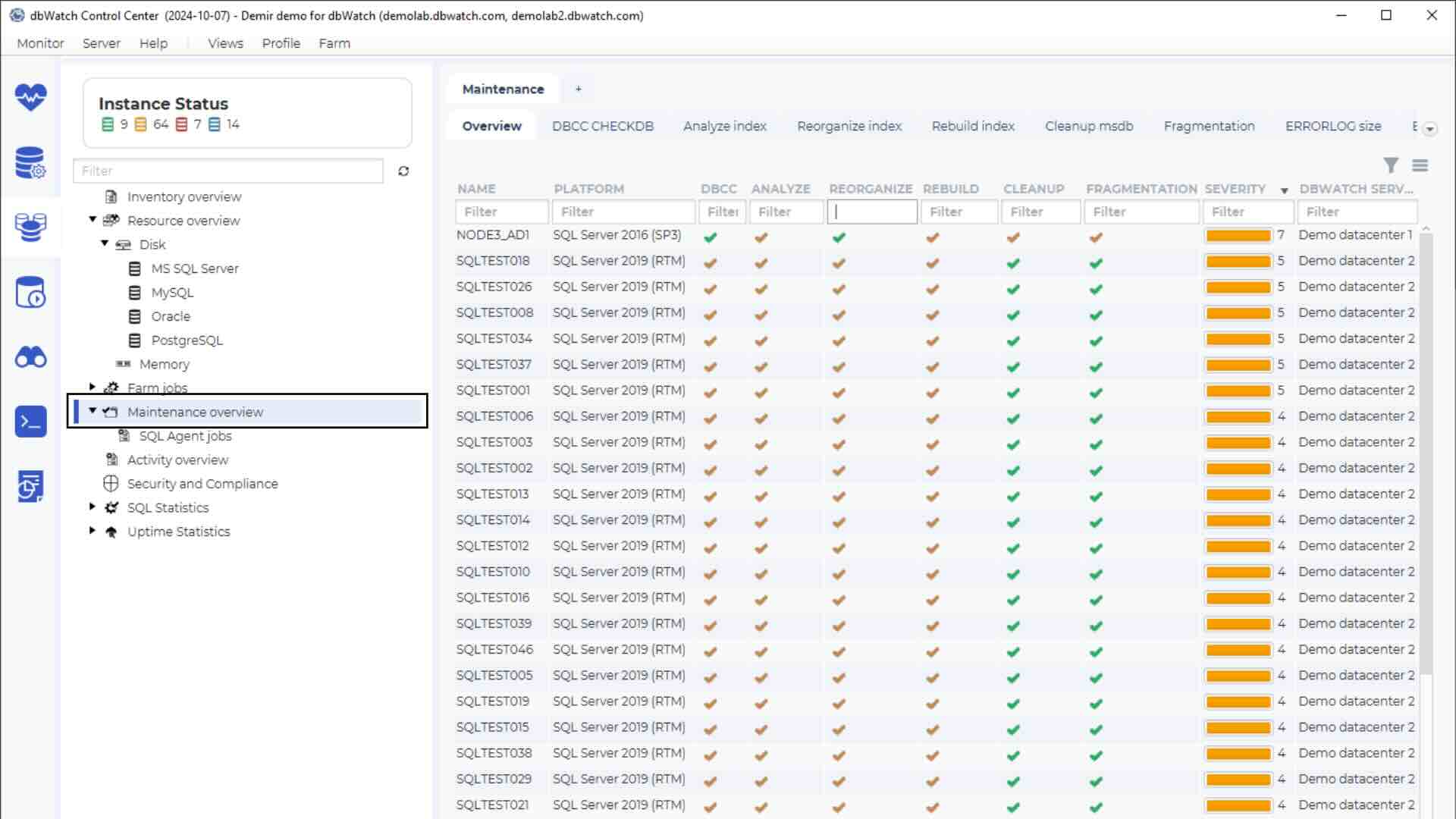
You feel like you are running blind. What you need is a top-level view. You want a way of looking at all of your instances as if they were one large database.
Proactive vs. Reactive Database Management
The immediate advantages of a proactive approach are fairly self-evident. Too often, database administration is centred around critical event response. You respond to a problem when it occurs; if nothing bad is happening, the assumption is that nothing should be changed (i.e. “If it isn’t broken, why fix it?”) However, when something does go wrong, this can be mission-critical.
If you are only working when something has gone wrong, you are likely missing a lot of invisible problems. It’s extremely difficult to handle these issues if you don’t even know when they are occurring. A view of a single instance at one time may not show any problems, however, you could be suffering slow-downs (or worse; dropped transactions) due to minor crashes, and dropped indexes at times when you are not looking at the specific location where the problem occurred.
If you are running at a high volume, a few seconds per transaction may not seem a lot. However, small occurrences can build up quickly. A few milliseconds per transaction can have ripple effects across an entire organisation.
Imagine sales volume; If you are running an online system, where your users are customers, human behaviour being what it is, your business could be losing potential customers. For instance, in the US, on recent tax deadline, many users were unable to file their returns due to high volume. The IRS’s databases could not handle the volume of transactions. While the federal government will always get its “business,” this is clearly not the case for many private enterprises. For each second lost, you can lose users and business. Evidence shows that user patience has decreased at an inverse relationship to the speed of transactions. At this point, most people will give up on an action if it takes 10 seconds or less.
This is worse if the transaction never goes through.
If you can have a higher-level view of how your system is running, you can be much more proactive in your maintenance and stop problems before they occur.
Database Design Decisions
All of those great ERDs you built may not have accounted for usage. Some portions of your system may be getting considerably more traffic than others. Your designs may not be accounting for the true business needs. Worse still, you have certain areas of the business that are suddenly making decisions and creating their own uses without notifying you.
With a good top level view you can get an idea where certain areas may need some re-indexing, and maybe some different workflows in your scripts. You may realise a possible need to re-design at least some segments of your structures or applications.
Resource Deployment
It could be that some instances are getting hit more frequently, depending on the time of day, physical location of servers and traffic. If you can see a higher level view, you may realise that certain parts of your database may need more attention during specific times. You can run some scripts to handle some of these load problems, but it would be a lot easier to know where and when to deploy these.
Platform Selection
As is sometimes the case, you may be (for whatever reason) running some instances or different platforms, or at the very least you may wish to test the function on different platforms, be it Oracle, SQL Server, PostgreSQL, or even MySQL/Maria. A more visible reporting system can help you identify and test which platforms work best; it could be that some parts of your DB might need to be segregated into a separate system.
Human Resource Needs
Of course, you can’t automate everything. No matter how well you designed your system, you are likely going to need DBAs to manage it. A good high level view of your DB will give you a better idea about which pieces need attention. You may have too many cooks, and it may mean that some are duplicating their tasks. If you can see existing patterns, it may be easier to create scripts to handle some
of those functions, and redirect your personnel to areas where they can provide the greatest benefit.
If you consider all of these factors, it’s not a stretch to recognise that the larger it grows, the more you need a method for gaining a greater level of visibility to manage your databases. To ignore this can result in seriously negative repercussions for your organisation. However, if you plan based on actual real-time data, you can head off many of these problems before they occur.
—–
To discover how dbWatch can give you the freedom to monitor all of your database instances, in real-time, across multiple platforms in an all-in-one solution, contact the team today.